I am currently looking for a used car, old but good enough for lasting a few years.
Since I never owned a car, and I lack the anecdotal experience of the car market that many people have, I am likely going to buy a lemon.
Well, let me try to buy a cheap lemon at least.
Autoscout24
I think autoscout24.it is the eBay of used cars in Italy. The website lists many offers from car dealerships and private sellers, with powerful search functionality and a nice looking, website free of ads.
Autoscout24 does offer a RESTful API, but it seems targeted to dealerships.
The best way for getting the data would be to find out how the website or the mobile app uses the API. This is what you want to do if you want to build a program that lasts for more than a few months. However, this could take some time since it involves inspecting the traffic and possibly some reversing.
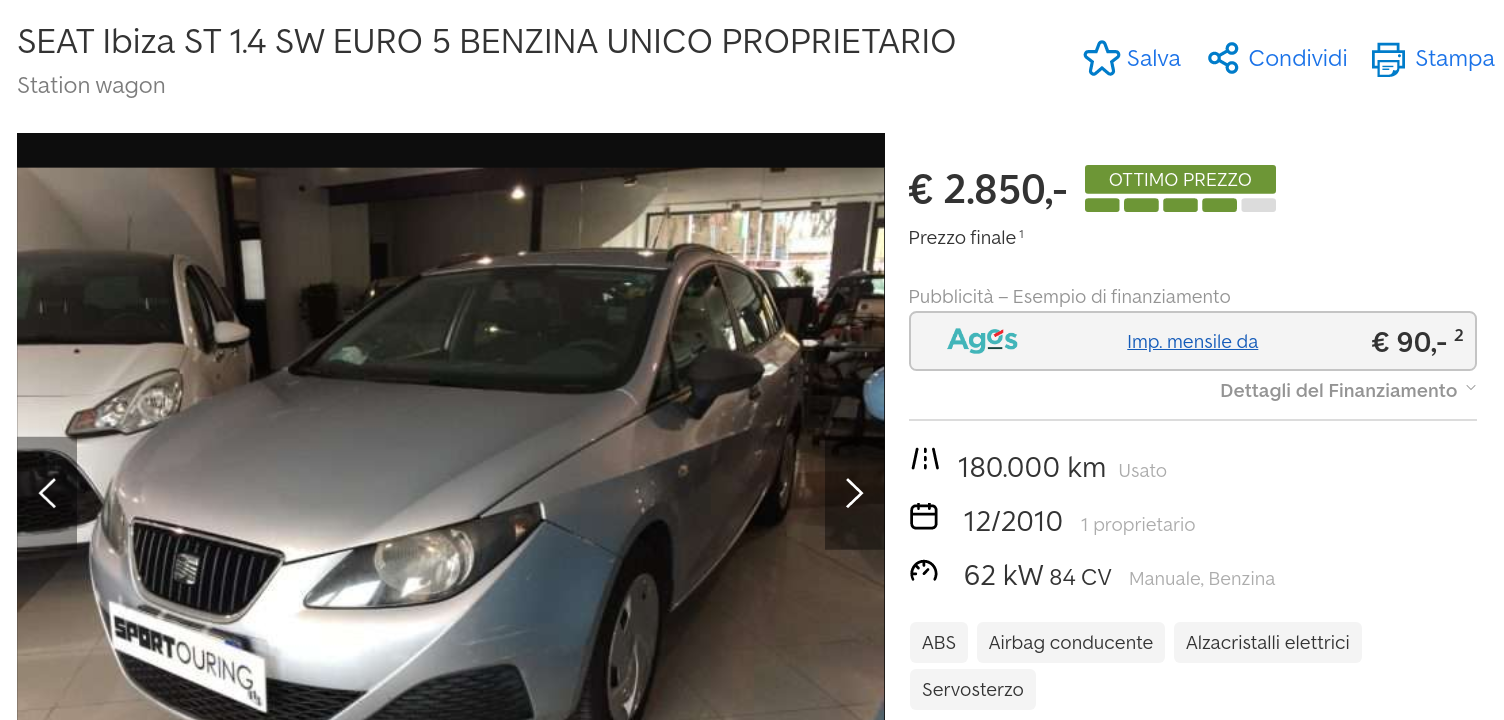
Let’s look at one page from the website instead:
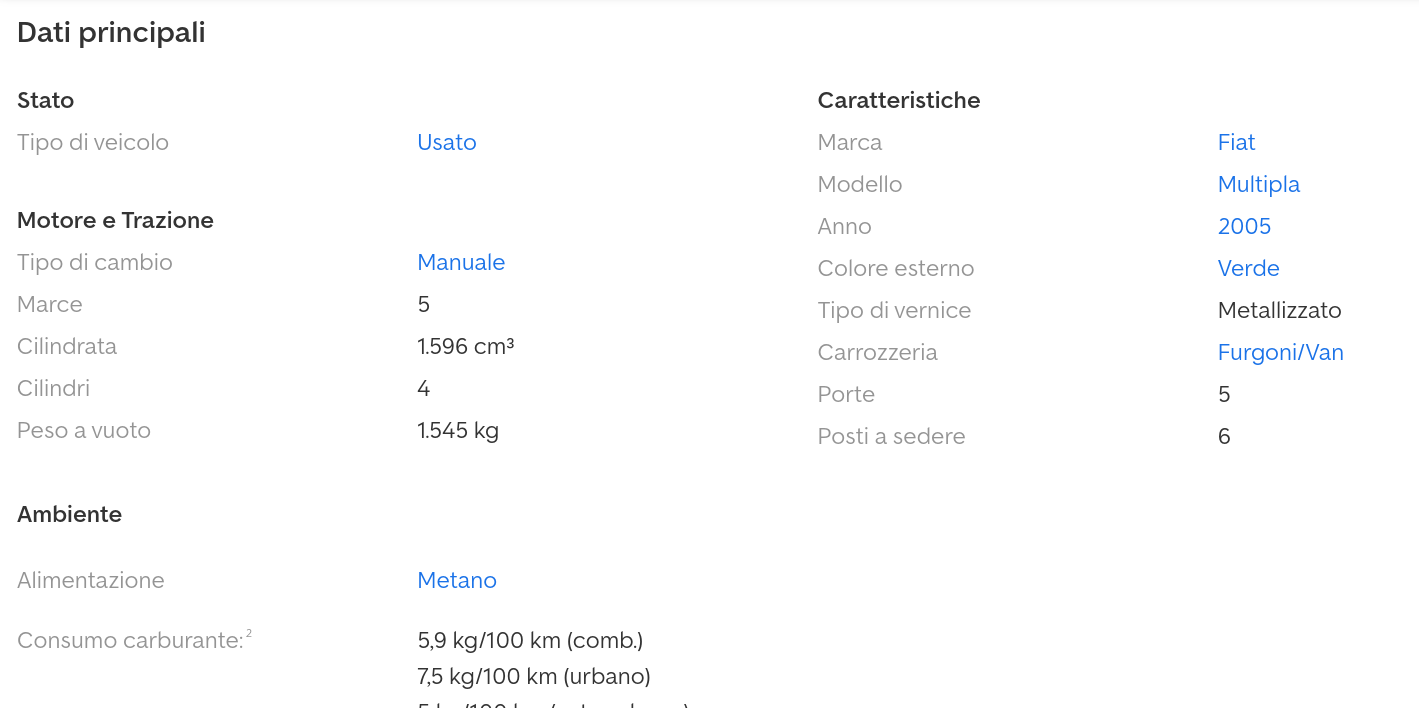
That’s it. A simple table with the details we need. That’s really easy to parse with xpath.
How does the search work? You can choose many fields:
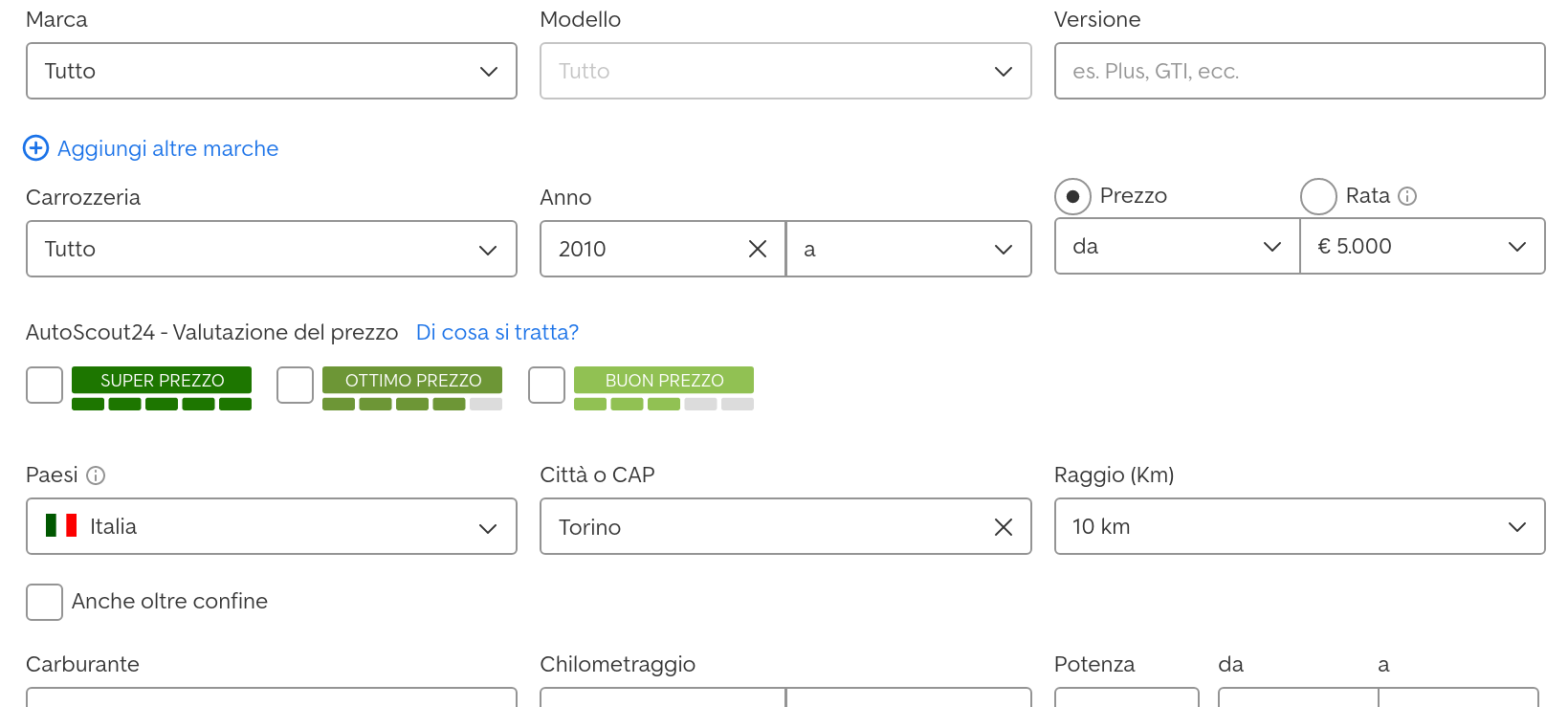
Let’s run the search and inspect the url:
1
| |
all the query parameters are nicely listed in the url. We can easily run any query.
Scrapy
Scrapy is a well-designed python framework for scraping. It provides all the functionalities you need while taking care of the boilerplate code.
You can use its shell to quickly play with xpath and css selectors. Just start it with an url:
1
| |
and you get an IPython environment where the webpage result is ready to be processed.
Once you find out how to get the data you need from the page, you write a Spider. The core of a Spider is just a single parse() function, where you process the response of a GET request.
parse() conveniently uses the yield mechanism for processing each page. After extracting the data, you yield a simple dictionary (representing a single car in our case). This dictionary is appended to a designed output file (e.g. a simple csv).
Then, you yield a new GET request so that you will process the next pages.
Less than 200 lines of python are enough for creating a dataset from autoscout.
Preview of the Dataset
I would have preferred to use Julia for this job, but there are no good scraping libraries currently. So, I will just use it for the data analysis part.
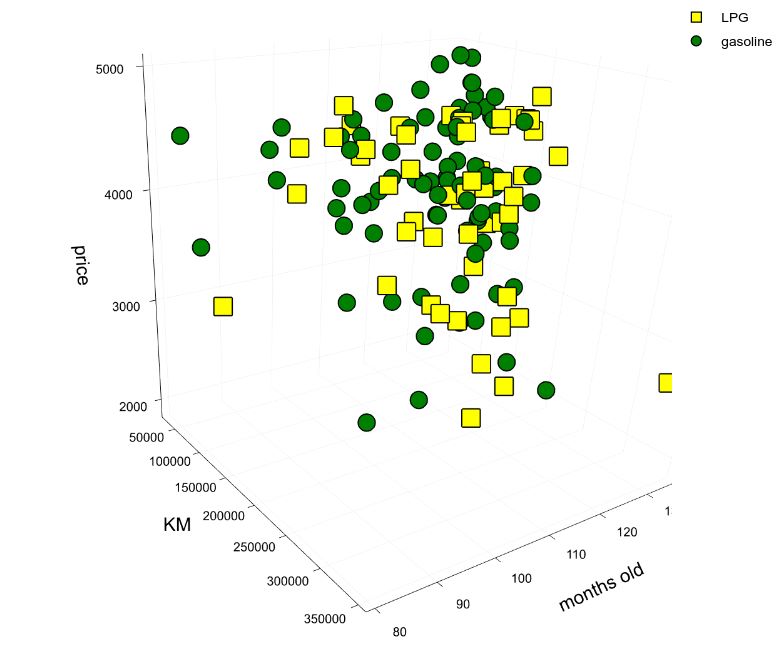
Let’s look at the dataset:

As you can see, I am interested in just a few properties: price, mileage (km), matriculation date, fuel, etc. There is some missing data, we will deal with it later. The dataset includes about 2000 vehicles from sellers in Turin.
I selected gasoline or LPG vehicles due to traffic restrictions rules in my city. I don’t really care about horsepower or model. Any 10 years old vehicle in the low price range will work for me. However, I will try to use many parameters for building a proper model for price prediction. Every time I will find a car I like, I will compare its price against the predicted one.
Actual analysis will be performed in the next post. Prepare yourself for a heavily technical post full of pie charts and linear regressions.
You can find the scraper code here.
Update 2021-04-01: as usual, my interests shifted on other stuff, so I am not going to write the second part of this blog post :P